
Benefits of CI/CD Pipelines
With outgrowing technology and amount of services around us manual integration and deployment process is no longer the right approach to build and ship your projects safely. Small and large businesses builds and ships their products more often than it was years ago. It is said that each day there is over a billion builds triggered. Can you imagine each of them started manually? I certainly can’t.
That’s when CI/CD pipelines come handy. CI/CD is a concept of delivering any application to a production environment with safety, speed and reliability and as least as possible impact on the customer side. It can be a manual process but in most cases, it’s fully automized and sometimes it will require pressing just one button in some CI/CD tool’s dashboard.
What is the process?
For any software that is built these days, there should be a CI/CD pipeline that will consist of individual steps responsible for different elements of the integration and deployment process.
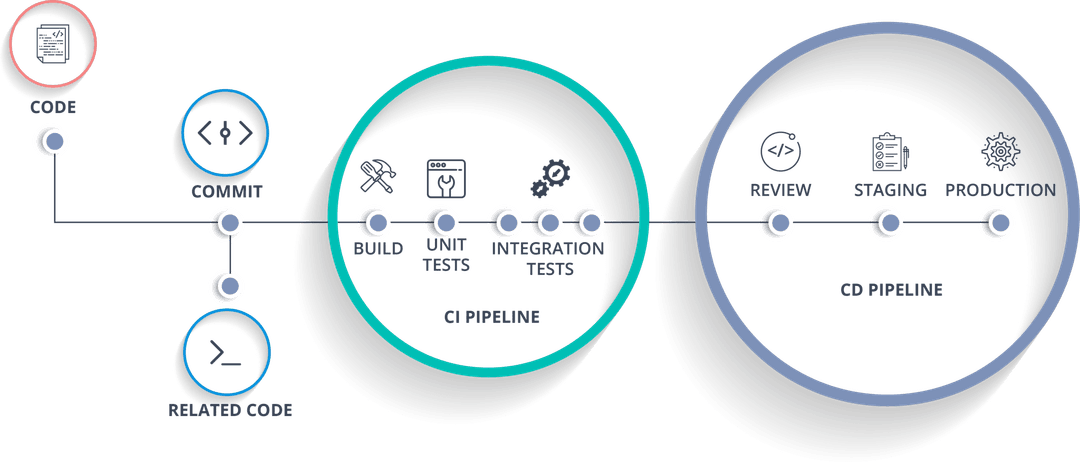
Continuous Integration (CI)
When working in teams or even individually it is crucial to know that the code that is getting produced is reliable and stable. That’s where CI practice comes in handy. That’s a part of the CI/CD process which gets triggered each time the developer pushes a code change to the repository. That is when verification of newly created code should happen. It’s responsible for proving that the new code doesn’t break existing functionalities and integrates with current business requirements or alarming developers that there are some issues with it. Thanks to it the developers can take action before the code gets to production. Usually, it consists of two or more steps which are: build the project -> run unit tests -> run integration tests. More sophisticated pipelines would integrate with additional tools (such as SonarQube) in further steps to provide a detailed report on the quality of the code. A best practice is that the CI pipeline is getting triggered whenever any push to the repository happens.
Continuous Delivery (CD)
Continuous Delivery is a follow-up of the Continuous Integration step and is responsible for getting the code changes deployed into the live environment. Thanks to this step being after CI we have certainty that the code is in the deployable state even if there were thousands of code commits done by multiple developers. In most cases, CD pipeline will get triggered only when push happens to certain branches (master/develop/tag) but it can vary based on companies' standards. Also in some cases, CD pipeline will be executed automatically or manually.
CI/CD tools
Nowadays there are numbers of tools that can be used for automated CI/CD process for any software. This can be done in Jenkins, Gitlab CICD, Bitbucket pipelines or if the code is hosted on cloud infrastructure Azure Pipelines, AWS Code Build and Code deploy or Code Pipeline. Most of those tools have numerous plugins and integrates with currently used project management tools. When all of that is properly configured life of any person involved in the development becomes much simpler as those plugins are capable of relating code commits with tasks in a way that the whole development history can be accessed from one place.
CI/CD use case
Let’s get some hands-on CI/CD process. Let’s say that you’ve been asked to set up CI/CD pipeline for a corporation that has several microservices that integrates with other various products and you are responsible for preparing CI/CD pipeline for one backend microservice written in Java >>.
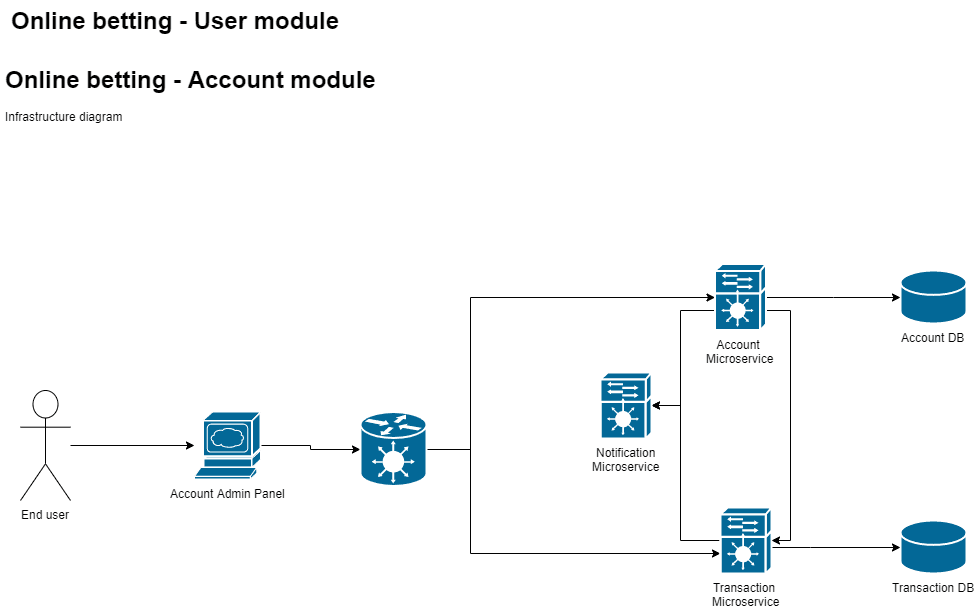
How should then such pipeline look like? Let’s have a look at some most popular approaches here:
For this use case, we will be using GitLab CI and will focus only on the account microservice and has pom configured with appropriate execution goals. It’s a quite popular tool these days especially because it comes along with the GitLab repository and the CI/CD pipeline configuration sits within the project code in .gitlab-ci.yml file.
CI Pipeline
For this case we want that CI pipeline consist of three steps:
- build
- run unit tests
- run integration tests
So how can we achieve it with GitLab CI? Let’s have a look:
variables: MAVEN_OPTS: "-Dmaven.repo.local=.m2/repository -Dorg.slf4j.simpleLogger.log.org.apache.maven.cli.transfer.Slf4jMavenTransferListener=WARN -Dorg.slf4j.simpleLogger.showDateTime=true -Djava.awt.headless=true" MAVEN_CLI_OPTS: "--batch-mode --errors --fail-at-end --show-version -DinstallAtEnd=true -DdeployAtEnd=true" MYSQL_ROOT_PASSWORD: password MYSQL_DATABASE: accountDB MYSQL_USER: accountAPI MYSQL_PASSWORD: accountAPIpass stages: - build - test - integration-test build: image: jamesdbloom/docker-java8-maven stage: build script: - mvn -version - mvn clean install -DskipTests test: image: jamesdbloom/docker-java8-maven stage: test dependencies: - build script: - mvn -version - mvn clean test integration-test: image: jamesdbloom/docker-java8-maven stage: integration-test dependencies: - test services: - registry.gitlab.com/online-betting/mysql:latest - registry.gitlab.com/online-betting/transaction-service:latest - registry.gitlab.com/online-betting/notification-service:latest script: - mvn -version - mvn clean integration-tests -D spring.datasource.url=jdbc:mysql://registry.gitlab.com-online-betting-mysql:3306/accountDB -D online.betting.transaction.service.url=http://registry.gitlab.com-online-betting-transaction-service:8101 -D online.betting.notification.service.url=http://registry.gitlab.com-online-betting-notification-service:8102
The configuration above defines three stepped CI pipeline. The most interesting one is the integration test step, so let's have a bit closer look. For integration testing, we need some sort of data source and microservices that our account microservice talks to. The assumption here is that each microservice is dockerised and the docker images are held within GitLab docker registry. Within the .yml file we define that as a part of this step we want three other services running alongside – for that GitLab runner will pull latest images and start them up. After all that we can pass those to the integration-test goal as an environment variable. Those stages will be run for any code commit as we don’t specify a branch on which given step should be run. Below is a graphical representation of how will it look like on GitLab console:
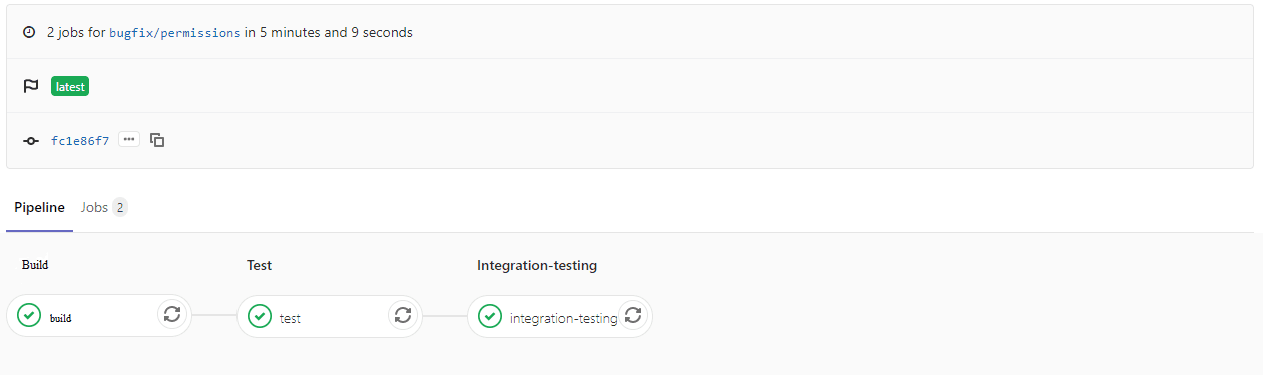
As a next step, this CI pipeline could generate code quality report and push it to third-party provider tools (such as SonarQube).
CD Pipeline
Let’s assume that the business has DEV, QA and PROD environment. For each deployment we want it to be manually triggered by the developer/DevOps. In such case our pipeline would consist of four steps:
- build docker image and push it to the repository with appropriate tag on it
- deploy feature branch to QA environment
- deploy develop branch to Dev environment
- deploy master branch to Prod environment
stages: .. - build-image-and-push - deploy-to-qa - deploy-to-dev - deploy-to-prod build: image: node:7 stage: build-image-and-push dependencies: - integration-test services: - docker:dind script: - cp app/target/*.jar docker/ - cp target/* docker/ - sh ci/script/login.sh - sh ci/script/push-to-ecr.sh deploy-to-qa: image: node:7 when: manual stage: deploy-to-qa dependencies: - build services: - docker:dind script: - cp docker/*.txt . - sh ci/script/login.sh - sh ci/script/deploy-to-qa.sh only: - /^feature.*$/ deploy-to-dev: image: node:7 when: manual stage: deploy-to-dev dependencies: - build services: - docker:dind script: - cp docker/*.txt . - sh ci/script/login.sh - sh ci/script/deploy-to-qa.sh only: - develop deploy-to-prod: image: node:7 when: manual stage: deploy-to-prod dependencies: - build services: - docker:dind script: - cp docker/*.txt . - sh ci/script/login.sh - sh ci/script/deploy-to-qa.sh only: - master
For given CD pipeline only the build-image-and-push is an automatic step and will be trigger only when integration-test step passes. The deploy steps are manual and branch-specific. We won’t go into the details how does the deploy-* scripts look like as they will be different per infrastructure type.
Future CI/CD suggestions
When working with microservices it is crucial to have CI pipelines that could tell us if the whole system is consistent across all the microservices that builds it.
For that, we should have a separate project that would consist of a set of end to end tests and its own CI pipeline that would get triggered when a push to any of the microservices projects that build the solutions happens. Such CI pipeline can be set up on Gitlab Ci or Jenkins or any other standalone tool such as https://concourse-ci.org >>.